There are many levels or degrees of complexity that can exist within queues. We will start with the simplest situation:
One way which may have come to mind is the addition of a second server or sprayer. In fact, it is through the analysis of queue formation and build-up that the appropriate number of check-out stations in supermarkets, post offices, booths in toll plazas, etc. are determined.
Note that as a result of the breakdown, items must wait to be processed, just as you do in a supermarket or doctor's office. The customers in this example (items waiting to be painted) don't get impatient, but people customers do. Usually customers want to be served without waiting "too long," and if that time is exceeded they will take their business elsewhere. Thus, one important measure of service performance is the average time which customers must wait in line for service.
Items move from machine A to machine B at the rate of 30 items per hour. Machine B is capable of servicing 80 items per hour. If machine B breaks down, a queue is going to form (items waiting to get into the production process.
Complete the following table.
| TIME FACTOR | WAITING LINE |
| Machine B begins | 120 |
| End of one hour | 70 |
| End of two hours | |
| End of three hours |
Complete the following table:
| TIME FACTOR | WAITING LINE |
| Machine B begins | 30t |
| End of one hour | 30t - 1(50) |
| End of two hours | 30t - 2(50) |
| End of three hours | |
| End of four hour | |
| End of M hours |
The smallest value of M (an integer) for which there is no queue is the smallest integer M for which M > ? .
A generalization: Items move from machine A to machine B at the rate of x items per hour. Machine B is capable of servicing y items per hour.
| TIME FACTOR | WAITING LINE |
| Machine B begins | xt |
| End of one hour | xt - (y - x) |
| End of two hours | |
| End of three hours | |
| End of M hours |
Have you used the fact that x < y in obtaining your result? What happens if x = y?
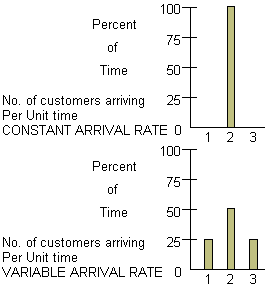
There are many application for which a constant arrival and process time are not acceptable. For example customers do not arrive at a fast food restaurant at a rate of exactly one each minute, nor does it take the same amount of time to serve each customer.
For the arrival rate situation, we do not know exactly how many customers will arrive during any unit of time. We only know that 25% of the time, 1 customer arrives in a unit of time; 50% of the time, 2 customers arrive per time unit; and 25% of the time, 3 customers arrive per time unit. It is usually assumed that the number arriving in one time unit does not depend on the number of arrivals in previous or subsequent time intervals.
Consider the service time situation shown below.
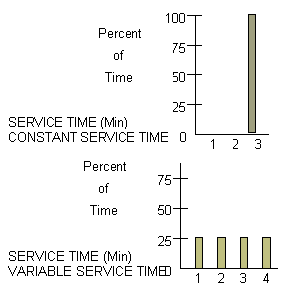
Thus, we see two different situations can have the same average service times. Simulation is a technique which can be used to mimic (model) real situations which include uncertainties. The simulation itself is a procedure which behaves like the real process.
We begin by selecting the number of arrivals at time = 0 according to this frequency data.
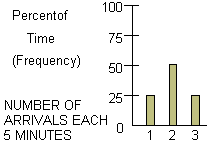
In this example we shall assume that all of the customers for a given five minute interval arrive at the beginning of the interval.
Now, how can we choose a number of arrivals? Clearly we want a way which is twice as likely to choose 2 arrivals as either 1 or 3. One way to simulate the number of arrivals at the beginning of a five-minute interval would be to choose at random an integer from 0 to 99. The phrase "at random" means every integer has an equal chance of being selected. We could simulate one arrival, if any integer 0 to 24 was chose, two arrivals if any integer 25 to 74 was chosen, and three arrivals if any of the 25 integers 75 to 99 was chooses. Clearly, this approach does fulfill our need to select two arrivals twice as frequently as either 1 or 3.
But these are exactly the frequencies at which our data told us that our arrivals should occur. Thus, to find the numbers of arrivals at t = 0 and t = 5, for example, all we need to do it (1) obtain 2 random integers from 0 to 99; (2) find the corresponding number of arrivals, and (3) mark them on the "arrival" line of our chart at the appropriate times. The process should be continued to find the number of arrivals occurring at the beginning of succeeding five minute intervals. It can also be noted that c1 begins service at t = 0. But how long is c1's service time?
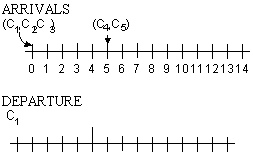
We now apply the same concept to determine service times for each of our five customers. The original service time chart appears below.
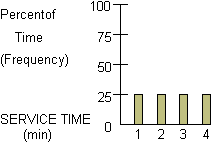
By selecting random numbers from 0 to 99, we can perform the calculations (e.g. average waiting time, time until first no-wait customer, etc). If we repeat the process with new random numbers, the results would be different. Therefore, if we want to get a true evaluation of such a variable rate process, the results of many such calculations should be reviewed and analyzed. For example, the waiting times should be computed for many repeats of the situation and reviewed to see the average, maximum, and minimum values that it takes on.